Here we are introducing the process of bulk loading of data from text file using HBase java client API. The worldwide Hadoop development community will learn in this post about bulk loading and when to use it and how its process is looks like.
We are introducing bulk loading of data using HBase bulk load feature using HBase java client API.
Bulk Loading:
HBase gives us random, real-time, read/write access to Big Data, generally we try to load data to HBase table via the client APIs or by using a MapReduce job with TableOutputFormat, but those approaches are problematic, Instead, the HBase bulk loading feature is much easier to use and can insert the same amount of data more quickly.
When to use Bulk Loading:
If you have any of these symptoms, bulk loading is probably a good choice for you:
- You needed to tweak MemStores to use most of the memory.
- You needed to either use bigger WALs or bypass them entirely.
- Your compaction and flush queues are in the hundreds.
- Your GC is out of control because your inserts range in the MBs.
- Your latency goes out of your SLA when you import data.
The bulk loading process looks like:
- Extract data from source(in our case from Text File).
- Transform data into HFiles.
- Loading the files into HBase by telling RegionServers where to find them.
So, after simple overview of bulk loading let us see a simple example by loading a comma separated text file into HBase using Bulkloading feature, To do this please follow below steps.
Environment:
- Java : 1.7.0_75
- Hadoop : 1.0.4
- HBase : 0.94.6
Prerequests:
- Data file (here we have comma separated user.txt as sample data file).
- HBase table must be present and the column family names must be same in HBase table and our bulk loading code.
- We have an HBase table “user” with 2 column families “personalDetails” and “contactDetails”
Our sample data file user.txt looks like:

It is stored as below format:
RowKey, First_Name, Last_Name, Email, City
For bulk loading our code looks like:
HbaseBulkLoadDriver.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseBulkLoadDriver extends Configured implements Tool {
private static final String DATA_SEPERATOR = ",";
private static final String TABLE_NAME = "user";
private static final String COLUMN_FAMILY_1="personalDetails";
private static final String COLUMN_FAMILY_2="contactDetails";
/**
* HBase bulk import example
* Data preparation MapReduce job driver
*
* args[0]: HDFS input path
* args[1]: HDFS output path
*
*/
public static void main(String[] args) {
try {
int response = ToolRunner.run(HBaseConfiguration.create(), new HBaseBulkLoadDriver(), args);
if(response == 0) {
System.out.println("Job is successfully completed...");
} else {
System.out.println("Job failed...");
}
} catch(Exception exception) {
exception.printStackTrace();
}
}
@Override
public int run(String[] args) throws Exception {
int result=0;
String outputPath = args[1];
Configuration configuration = getConf();
configuration.set("data.seperator", DATA_SEPERATOR);
configuration.set("hbase.table.name",TABLE_NAME);
configuration.set("COLUMN_FAMILY_1",COLUMN_FAMILY_1);
configuration.set("COLUMN_FAMILY_2",COLUMN_FAMILY_2);
Job job = new Job(configuration);
job.setJarByClass(HBaseBulkLoadDriver.class);
job.setJobName("Bulk Loading HBase Table::"+TABLE_NAME);
job.setInputFormatClass(TextInputFormat.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapperClass(HBaseBulkLoadMapper.class);
FileInputFormat.addInputPaths(job, args[0]);
FileSystem.getLocal(getConf()).delete(new Path(outputPath), true);
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.setMapOutputValueClass(Put.class);
HFileOutputFormat.configureIncrementalLoad(job, new HTable(configuration,TABLE_NAME));
job.waitForCompletion(true);
if (job.isSuccessful()) {
HBaseBulkLoad.doBulkLoad(outputPath, TABLE_NAME);
} else {
result = -1;
}
return result;
}
}HbaseBulkLoadMapper.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class HBaseBulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
private String hbaseTable;
private String dataSeperator;
private String columnFamily1;
private String columnFamily2;
private ImmutableBytesWritable hbaseTableName;
public void setup(Context context) {
Configuration configuration = context.getConfiguration();
hbaseTable = configuration.get("hbase.table.name");
dataSeperator = configuration.get("data.seperator");
columnFamily1 = configuration.get("COLUMN_FAMILY_1");
columnFamily2 = configuration.get("COLUMN_FAMILY_2");
hbaseTableName = new ImmutableBytesWritable(Bytes.toBytes(hbaseTable));
}
public void map(LongWritable key, Text value, Context context) {
try {
String[] values = value.toString().split(dataSeperator);
String rowKey = values[0];
Put put = new Put(Bytes.toBytes(rowKey));
put.add(Bytes.toBytes(columnFamily1), Bytes.toBytes("first_name"), Bytes.toBytes(values[1]));
put.add(Bytes.toBytes(columnFamily1), Bytes.toBytes("last_name"), Bytes.toBytes(values[2]));
put.add(Bytes.toBytes(columnFamily2), Bytes.toBytes("email"), Bytes.toBytes(values[3]));
put.add(Bytes.toBytes(columnFamily2), Bytes.toBytes("city"), Bytes.toBytes(values[4]));
context.write(hbaseTableName, put);
} catch(Exception exception) {
exception.printStackTrace();
}
}
}HbaseBulkLoad.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
public class HBaseBulkLoad {
/**
* doBulkLoad.
*
* @param pathToHFile path to hfile
* @param tableName
*/
public static void doBulkLoad(String pathToHFile, String tableName) {
try {
Configuration configuration = new Configuration();
configuration.set("mapreduce.child.java.opts", "-Xmx1g");
HBaseConfiguration.addHbaseResources(configuration);
LoadIncrementalHFiles loadFfiles = new LoadIncrementalHFiles(configuration);
HTable hTable = new HTable(configuration, tableName);
loadFfiles.doBulkLoad(new Path(pathToHFile), hTable);
System.out.println("Bulk Load Completed..");
} catch(Exception exception) {
exception.printStackTrace();
}
}
}To run the code follow below steps:
- Include all libraries from lib/
- Export project’s JAR to <YourProjectName>.jar
- Copy <YourInputFile>.txt to hdfs
- Create table using: create ‘<tablename>’, <ColumnFamily1>,<ColumnFamily2>
- Run the JAR file using: hadoop jar <YourProjectName>.jar <hdfsDirectory>/YourInputFile .txt <hdfsDirectory>/<outputname>/
- Modify MapReduce job for your needs
After running the code you can see the result using ‘scan‘ comand in HBase shell. Our output looks like:
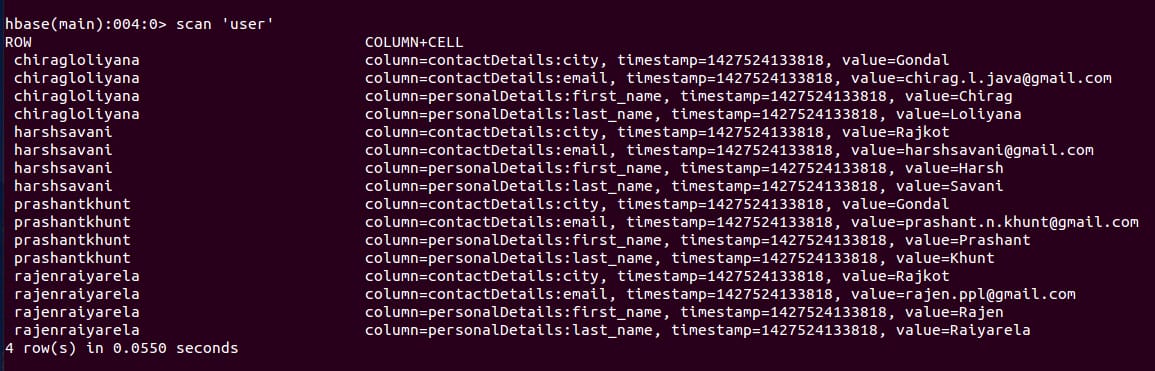
You can also find generated files for column families in hdfs. Our output folder in hdfs looks like:
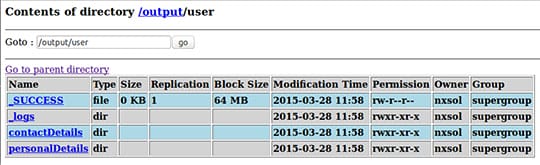
Code Walk Through:
- Most of the code is self-explanatory, so you can easily check and get line by line understanding of the code.
- We are extracting data from text file and putting the data in HBase Put in our HbaseBulkLoadMapper.java
- configureIncrementalLoad() method will generate HFiles.
- HbaseBulkLoad.java will load those generated HFiles into HBase table.
We hope the post has made you understand about the concept of bulk loading. This post was intended for helping big data and Hadoop development community in understanding bulk loading and its process.
This article is written by Samual Alister. He is an experienced Big Data Hadoop Architecture Developer working with Aegis Soft Tech. He is also deep experienced in a Hadoop architecture.





